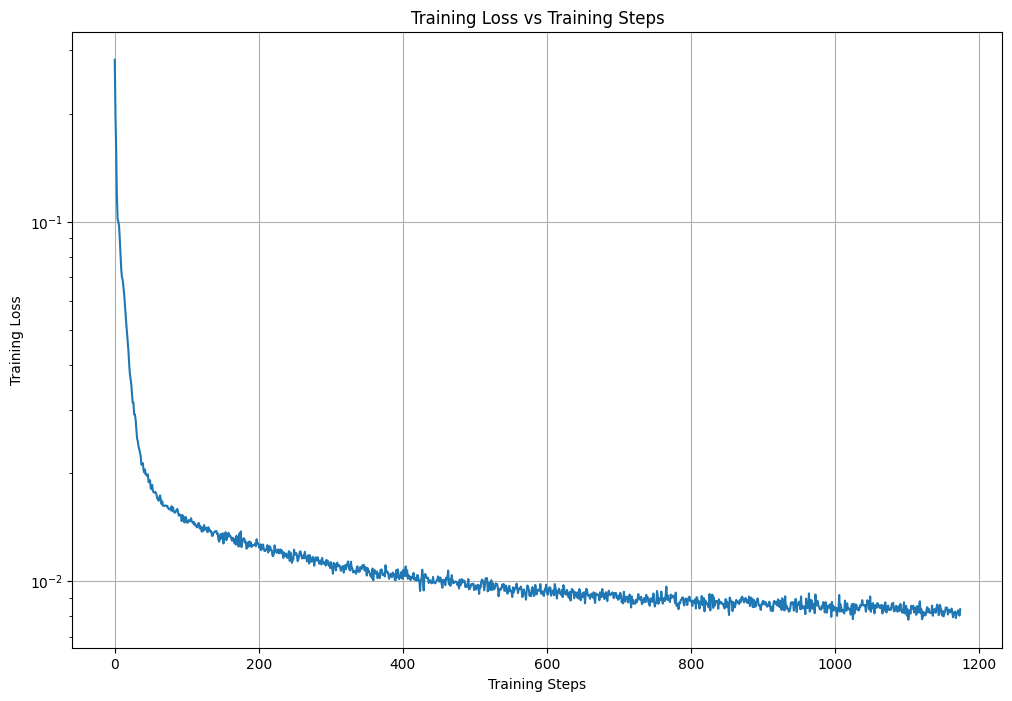
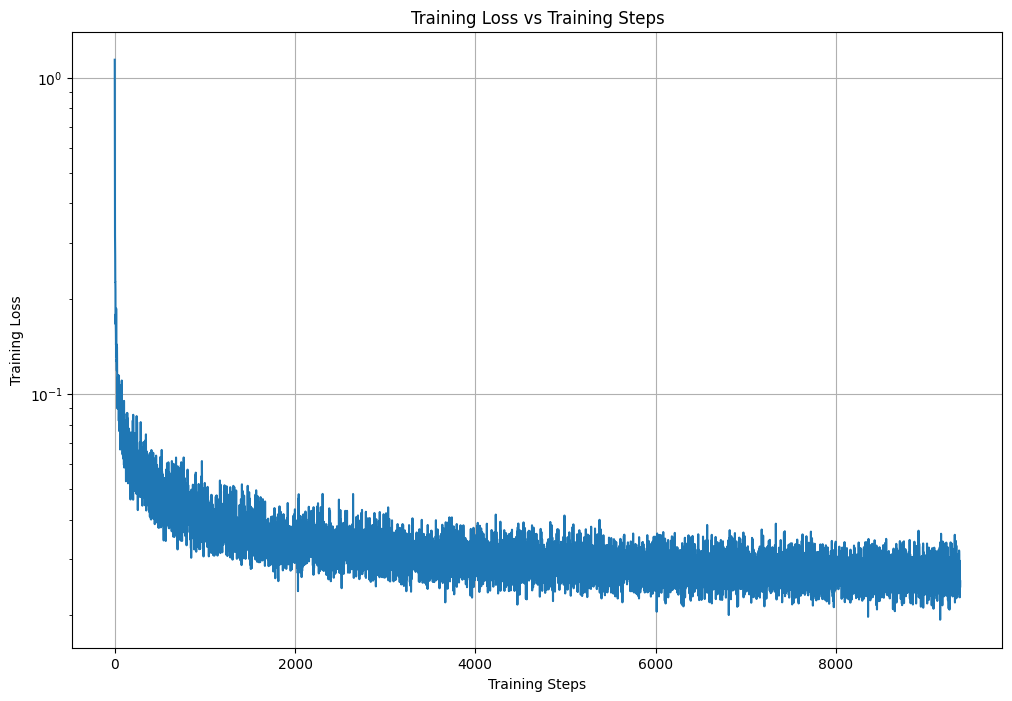
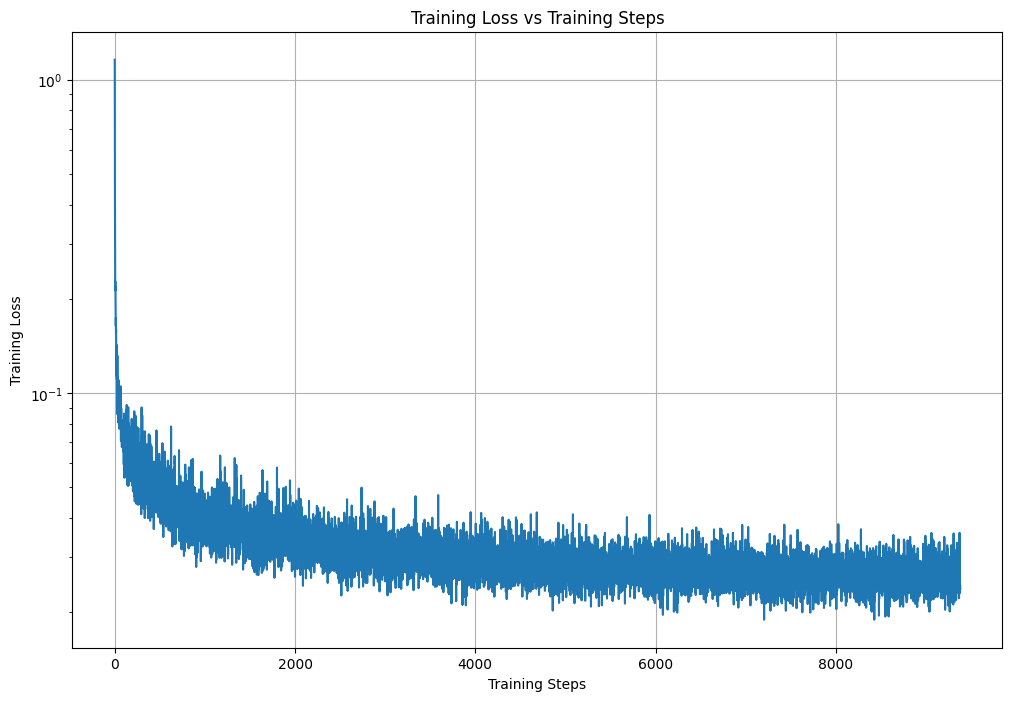
Part 0: Setup
For the setup part, I use DeepFloyd IF as the diffusion model. For Part A, I used the seed 180. Deepfloyd is a two-stage model. In the first stage, 64 x 64 images are produced and second stage takes these images and produces final images of size 256 x 256. To test the setup, I used the given prompts to generate the following outputs:

a man wearing a hat

an oil painting of a snowy mountain village

a rocket ship
The generated images actually represent the prompts pretty well. To test the effect of num_inference_steps on the outputs, I test the prompt 'an oil painting of a snowy mountain village' with num_inference_steps 7 and 46 in addition to 20 given above. Here are outputs with num_inference_steps 7 and 46 respectively:

an oil painting of a snowy mountain village (num_inference_steps = 7)

an oil painting of a snowy mountain village (num_inference_steps = 46)
With increasing num_inference_steps, the images become more detailed and better reflect the prompts.
1.1 Implementing the Forward Process
Now, I implement the forward process. For the forward process, given a clean image, I get a noisy image for a timestep t by sampling noise from a Gaussian. In addition to these, I also scale the image. The original Campanile image is shown below at different noise levels. Larger t represents larger noise.
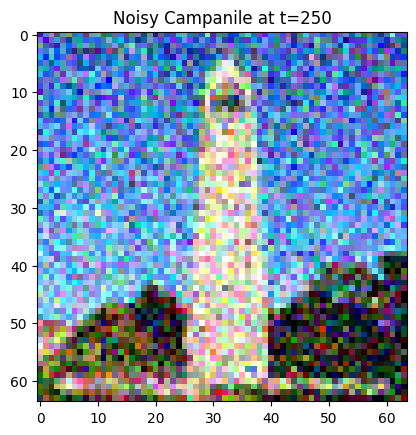
Noisy Campanile at t=250
Noisy Campanile at t=500
Noisy Campanile at t=750
1.2 Classical Denoising
In this section, I use classical denoising to denoise the noisy images produced in the previous part. For classical denoising, I take a noisy image and try to denoise it by Gaussian filtering. Here are the results for different timestamps:
Noisy Campanile at t=250
Noisy Campanile at t=500
Noisy Campanile at t=750
Classical Denoised Campanile at t=250
Classical Denoised Campanile at t=500
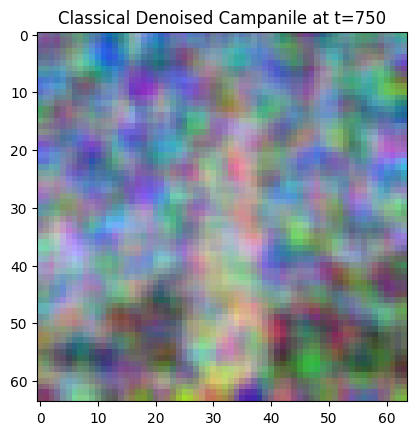
Classical Denoised Campanile at t=750
1.3 One-Step Denoising
For one-step denoising, I use a pretrained denoiser stage_1.unet to find the noise in the images. This UNet is already trained on a very large dataset but it was trained text conditioning so I use the embedding of the given prompt "a high quality photo” for conditioning. Then, I remove this image to recover a clean image for noisy images produced in part 1.1:
Noisy Campanile at t=250
Noisy Campanile at t=500
Noisy Campanile at t=750
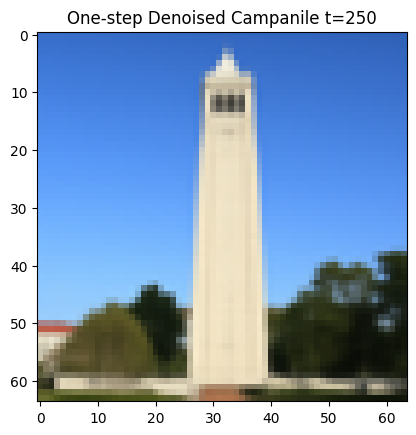
One-Step Denoised Campanile at t=250
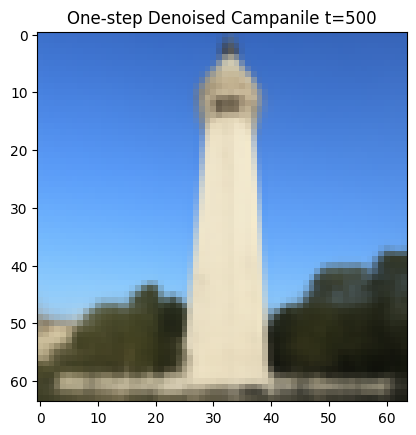
One-Step Denoised Campanile at t=500
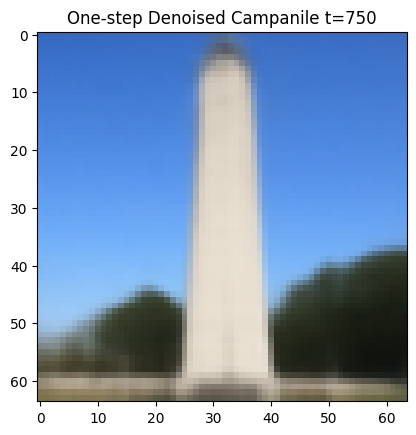
One-Step Denoised Campanile at t=750
1. 4 Iterative Denoising
In the previous part, performance gets worse with more noisy images. To combat this, I will implement iterative denoising. For iterative denoising, I create a new list of timesteps,strided_timesteps, to skip some steps. The stride of steps will be 30. I add noise to the test image at timestep[10] and run the implemented iterative_denoise function on this image with i_start algorithm being 10. In the following, denoised image is displayed at every fifth step and final clean image prediction is shown in comparison to other techniques:
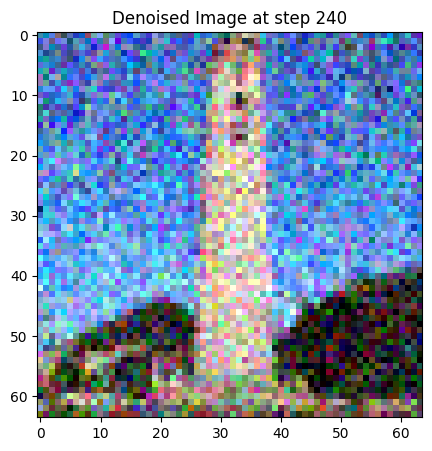
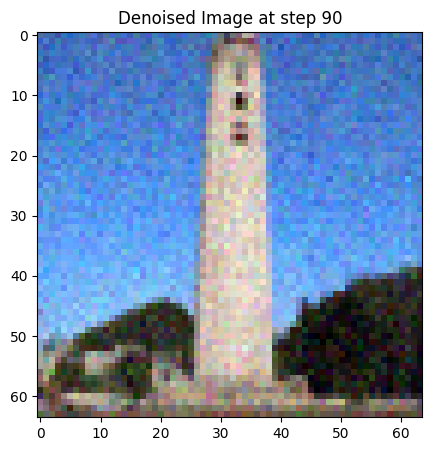
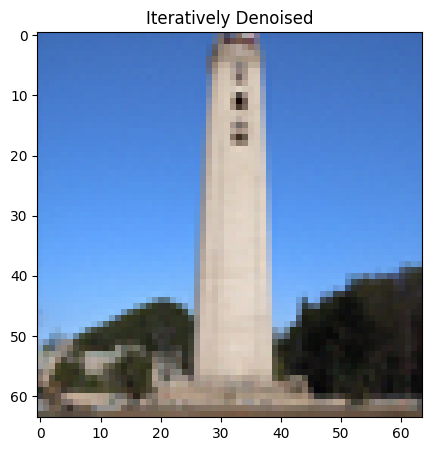
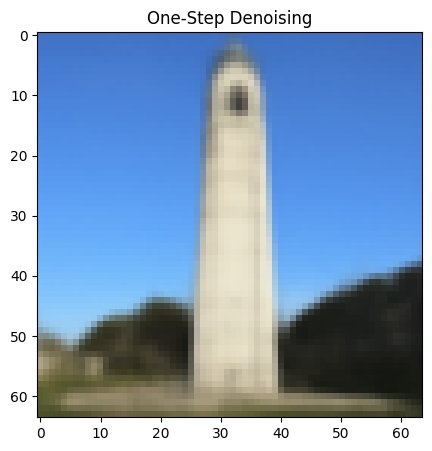

1.5 Diffusion Model Sampling
For this part, I use iterative_denoise function I defined earlier to generate images from scratch by passing 0 as the i_start argument. I also pass in random noise, and the function denoises pure noise. Here are 5 samples with the prompt “a high quality photo”:





1.6 Classifier-Free Guidance (CFG)
The quality of the results in the previous section were not great. To significantly improve image quality, I will use CFG in this section. For CFG, I compute both conditional and unconditional noise estimate. In CFG, we have a hyperparameter, named scale in the function, that determines its strength. When scale is 0, CFG is essentially unconditional noise estimate but when scale is bigger than 1, CFG can produce much more quality images. Here are 5 samples from CFG with scale=7 and prompt “a high quality photo”:





1.7 Image-to-image Translation
In this section, I follow the SDEdit algorithm. I noise the original image a little bit first, then, force it back to the image manifold without conditioning. As a result, I get an image similar to the original image. For this section, I will use the 3 test images, one of them being the Campanile photo. Here are the edits of the test images, at different noise levels 1, 3, 5, 7, 10, 20 with "a high quality photo":

i_start=1

i_start=3

i_start=5

i_start=7

i_start=10

i_start=20
Original Campanile

i_start=1

i_start=3

i_start=5

i_start=7

i_start=10

i_start=20

Original Golden Gate

i_start=1

i_start=3

i_start=5

i_start=7

i_start=10

i_start=20

Original cat
1.7.1 Editing Hand-Drawn and Web Images
The technique I used in the previous section also performs pretty well for nonrealistic images that is projected it to the natural image manifold. To test for these, I will use 1 image from web and 2 images by my hand drawing:

i_start=1

i_start=3

i_start=5

i_start=7

i_start=10

i_start=20

Original UP

i_start=1

i_start=3

i_start=5

i_start=7

i_start=10

i_start=20

Original Hand Drawing 1

i_start=1

i_start=3

i_start=5

i_start=7

i_start=10

i_start=20

Original Hand Drawing 2
1.7.2 Inpainting
Based on the Repaint paper, I implement inpainting in this section using the same procedure. Given a mask, when I run the diffusion denoising loop, I replace everything except the mask area with the original images but with the added noise based on timestep t. So, new content is only produced in the pixels where mask has value 1. Here are my results for inpainting:

Original

Mask

To Replace

Final

Original

Mask

To Replace

Final

Original

Mask

To Replace

Final